From Data to Actionable Insights: Harnessing the Power of Business and Social Analytics
HKUST’s Center for Business and Social Analytics (CBSA) generates quality insights from massive amounts of social data.

[Sponsored Article]
British mathematician Clive Humby famously coined the phrase “Data is the new oil” in 2006. Since then, many organizations have scrambled to embrace this maxim, ensuring they have a robust data strategy to inform decision-making for every function from finance to marketing and logistics to production.
Today, data is being generated, stored, and analyzed at staggering rates worldwide. According to a Forbes study in 2018, over 2.5 quintillion bytes of data are produced in the digital universe every single day. Along with this rapid growth of data, the rise of social media has encouraged researchers and data users to tap unconventional data sources and methods to explain and predict economic or behavioral outcomes in various domains such as finance (e.g., stock price), marketing (e.g., brand reputation, consumer purchasing behavior), and politics (e.g., voting behavior).
Unconventional data, more commonly referred to as big data, is unstructured and undefined. Such data is characterized as high-volume, high-velocity, high-variety, and/or highly semantic, and advanced techniques and applications, as well as high-performance computing, are often required to collect and process it. Big data analytics, including data mining methods and machine learning algorithms, allow users to gain a deep understanding of behavior.
The Internet has become a part of modern life, and it is almost second nature for people to express their views and preferences on social media. The emergence of platforms such as Facebook, Uber, Taobao, and peer-to-peer applications, and new computing and communications technologies such as Internet of Things (IoT) and 5G cellular networks, has generated tremendous amounts of new data that opens up the possibility to study a wide range of human behaviors.
Against this backdrop, the Center for Business and Social Analytics (CBSA) of the HKUST Business School leverages massive amounts of social big data to generate quality insights that aid business and social decision and policy making. To date, a majority of academic and industry research is based on conventional data from opinion polls, surveys, and lab or field experiments, which suffer from sample selection bias or lack generalizability. The Center takes advantage of social big data to tackle complex business and social problems by listening to what the crowd actually says. The following are sample projects undertaken by the Center.
Hong Kong Tourism Index
The tourism industry is one of the four pillar industries in Hong Kong. Mainland China is the major tourism market of Hong Kong, accounting for nearly 80% of visitor arrivals in 2019. In view of the tendency of Chinese tourists to share their travel experiences and sentiments on social networks, the Center has collaborated with Wisers, the world's leading expert in big data and AI analytics, to construct a series of predictive tourism indexes for government monitoring and other business interests.
We collect massive volumes of data from digital platforms frequently used by Chinese travelers, including Sina Microblog, Baidu Tieba, Douban, Mafengwo, Xiaohongshu, and Douyin. The total amount of data extracted from these platforms exceeds 10 million observations per day. To account for the seasonality in tourism demand and key sociopolitical events in Hong Kong, we focus on the period of January 2018 to December 2020. It is imperative to gain a systematic understanding of the various factors impacting Hong Kong's tourism industry.
We draw on the latest natural language processing technologies and advanced statistical models to process and quantify the data, and establish a multivariate time series forecasting model and a series of predictive indexes that are updated in real time. With the error rate as low as 4% (in terms of Symmetric Mean Absolute Percentage Error, sMAPE), these indexes predict the occupancy rates of Hong Kong hotels, the number of visitors to Hong Kong, and the average daily rates of Hong Kong hotels.
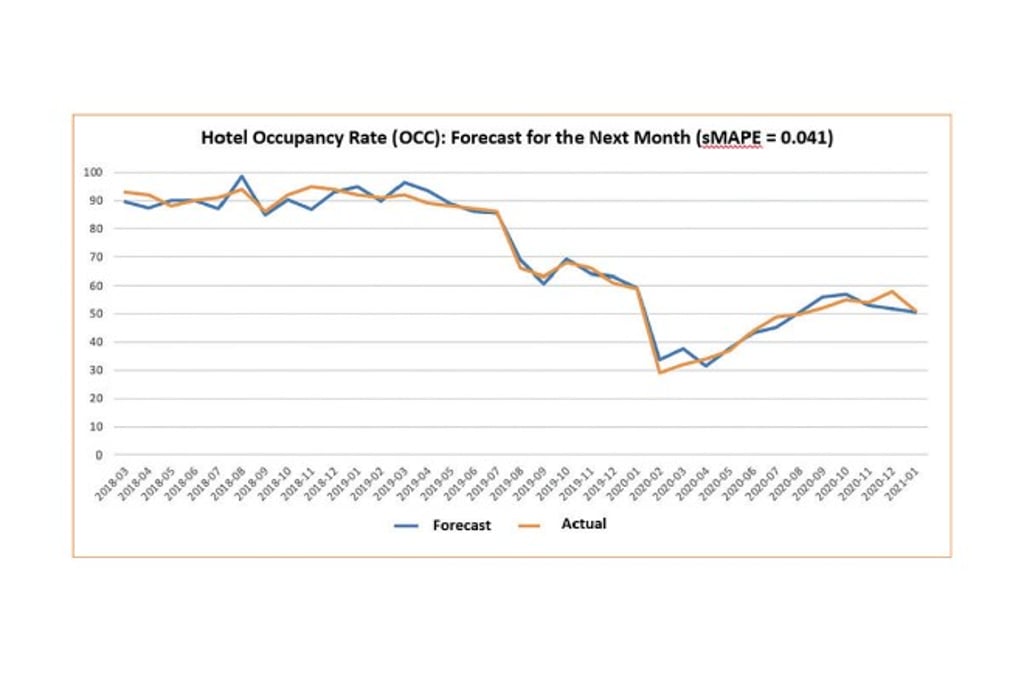
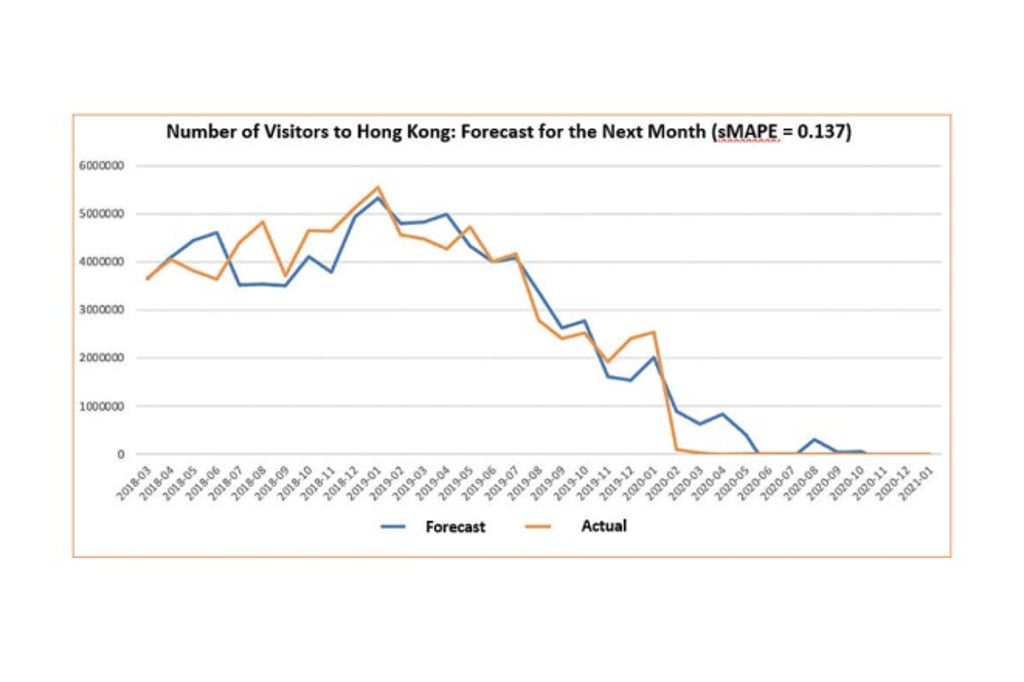
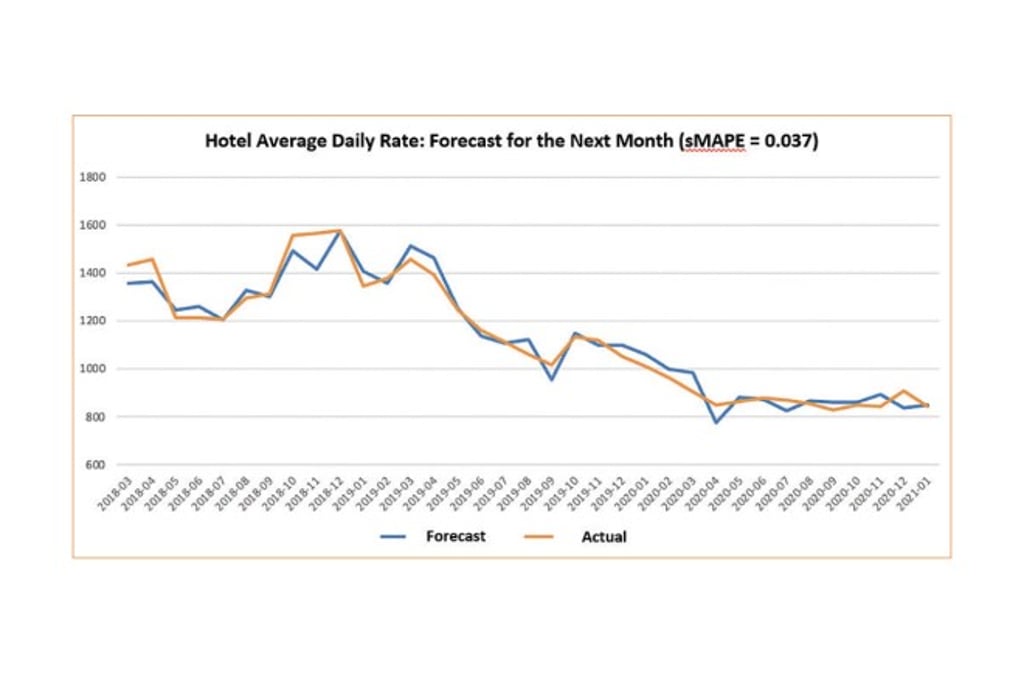
We anticipate that our work will enable the Hong Kong Government and the tourism industry to obtain accurate forecasts, trends, and insights in the future concerning the local tourism industry, and formulate more sustainable and data-driven tourism policies and strategies.
FinSent – An Interactive Sentiment Analysis Dashboard Based on FinBERT
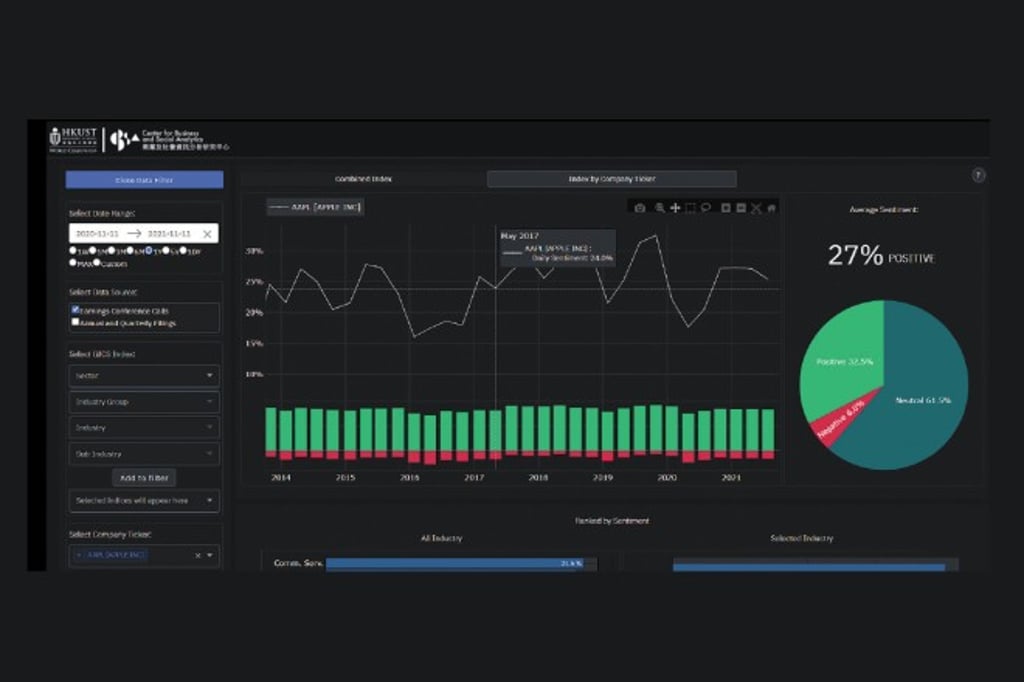
The Center has been developing a first-of-its-kind sentiment analysis dashboard based on FinBERT, a BERT model that outperforms other language models in the sentiment classification of financial texts. Aptly named FinSent, the fully automated dashboard visualizes sentiments of financial texts using cutting-edge natural language processing technologies, enabling users to gain insights into the financial sentiments of publicly traded companies through charts, graphs, and color-coded sentiment scores.
FinSent comprises an automated module that collects and processes corporate 10-K and 10-Q filings and earnings call transcripts of public companies on a daily basis. The sentiments towards the companies are presented via an interactive dashboard that allows users to freely customize the content. The following diagram shows an example of the FinSent interface:
Spillover of Social Media Sentiments
In recent decades, the rise of social media has aided the free flow of public information. It has also become a reliable platform for people around the world to interact and share their opinions in an affordable, anonymous, and uncensored manner. While countless benefits have been accrued from the use of social media, some complicated and worrying challenges have surfaced in recent years, catching the attention of researchers, policymakers, and members of the public. It is necessary to understand the difference between real-life and online communications, and how this affects our behavior and mental health.
To address this issue, we study the spillover of social media sentiments in the English Premier League (EPL) soccer community using data from Reddit. We apply sentiment analysis with a machine learning model to all the contents in our dataset to capture the sentiment of the contents. The model outputs the likelihood of those contents being positive, neutral, or negative.
We trace the contents created by each author and provide evidence of how their next sentiments will change from the current one with a transition matrix. The transition matrix shows that sentiments of the next content differ depending on their current sentiments. Users will more likely produce negative sentiment contents when they generate negative contents (42.39%). On the other hand, sentiments of the next contents are more likely positive when they produce positive sentiment contents (27.60%) rather than negative ones (17.09%). Thus, we consider the sentiment of the current content as one of the controls when we estimate the model.
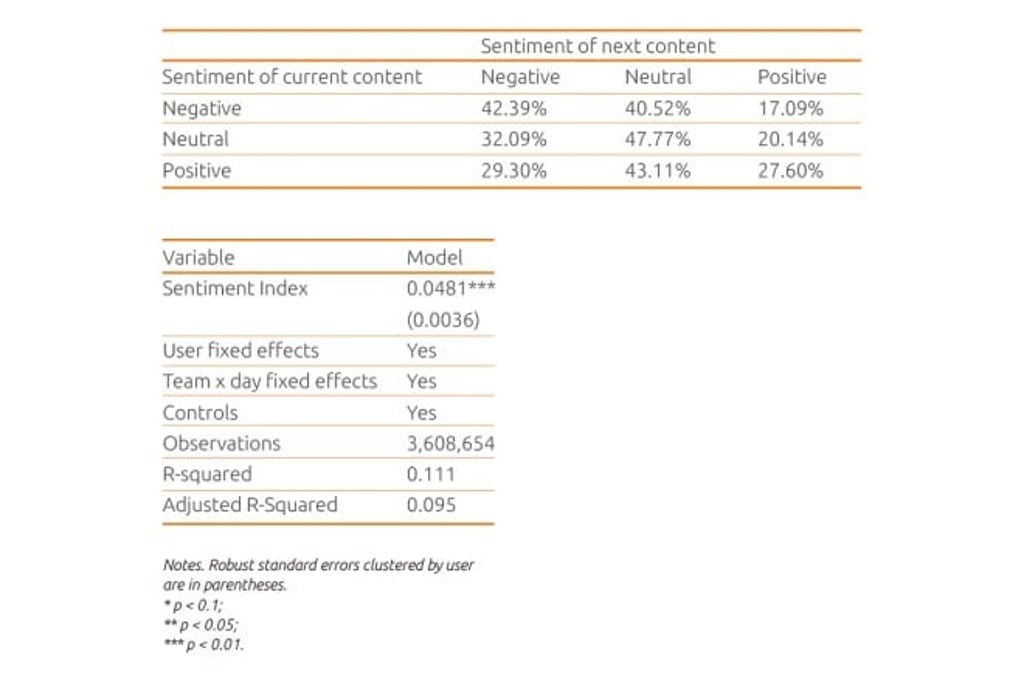
With 3.6 million pieces of content from 20 EPL subreddits in the 2017/2018 season, we run a regression model to check whether the sentiments of what users see would affect the sentiment of their next piece of content. The dependent variable of the model is the difference between the likelihood for the content to be positive and negative. A positive index means the content is more likely to be positive. Similarly, a negative index means the content is more likely to be negative. The main independent variable is a sentiment index, which measures the sentiments of contents that users see between their posts. Furthermore, we control various confounding factors, including the sentiment of their previous posts.
We find strong evidence of spillover effects from the sentiments. The estimate of the sentiment index (0.0481) is significant and positive. It means that emotions on social media are contagious and can easily intensify. Social media users should recognize this spillover to their emotions and avoid being manipulated by other social media users. Learning how to deal with an increasingly polarized online environment and offensive conversations is important if we are to be responsible netizens.
The National Security Law (NSL) and Social Media Sentiments
One of the Center's research projects investigates how the actions initiated by the different authorities—such as the Chinese government, HKSAR, and international governments—and the implementation of the NSL on 1 July 2020 influenced the sentiments in various media channels in Hong Kong. We construct our sentiment model through manual labeling and then train it by a state-of-the-art machine learning model called MacBERT. Based on the fine-tuned model, we predict not only the sentiments of conventional media (e.g., newspapers and magazines), but also social media (e.g., Facebook, LIHKG) users’ sentiments towards the China-Hong Kong relationship.
As a piece of model-free evidence, we depict the different trends of the daily proportion of sentiments (positive, neutral, and negative) across various media types. We observe that the total proportion of positive sentiment contents had increased during our empirical period (May 2020 to July 2020).
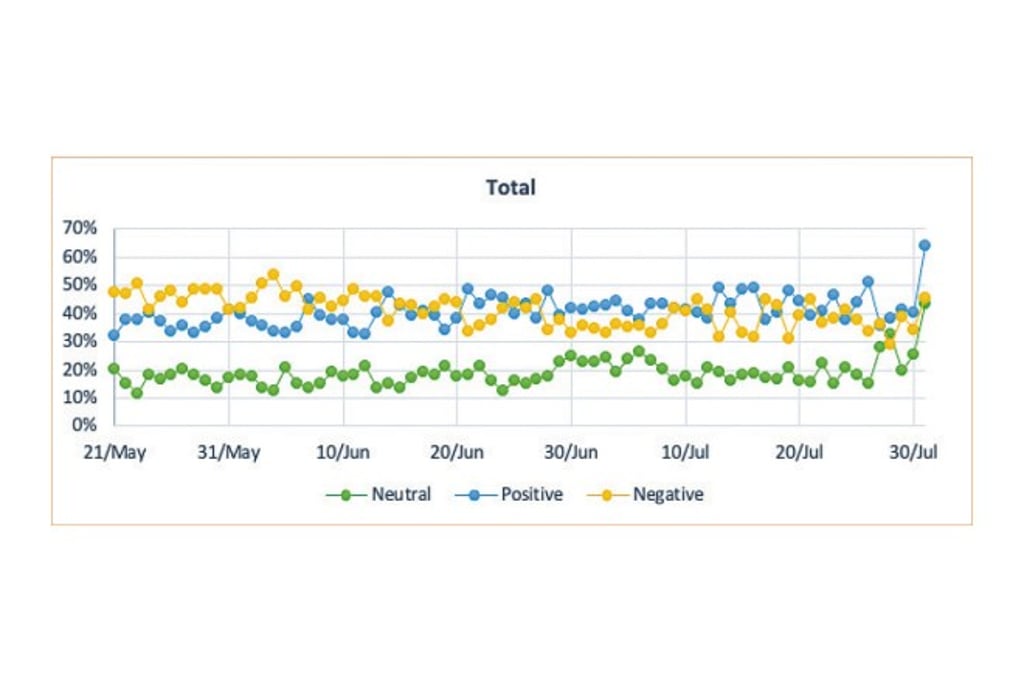
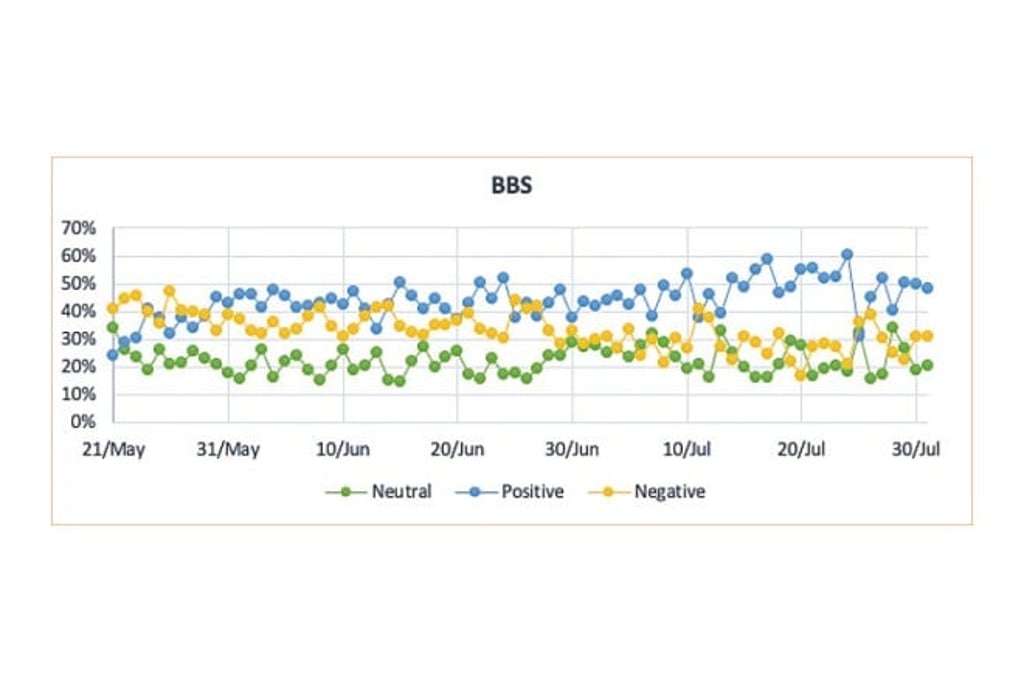
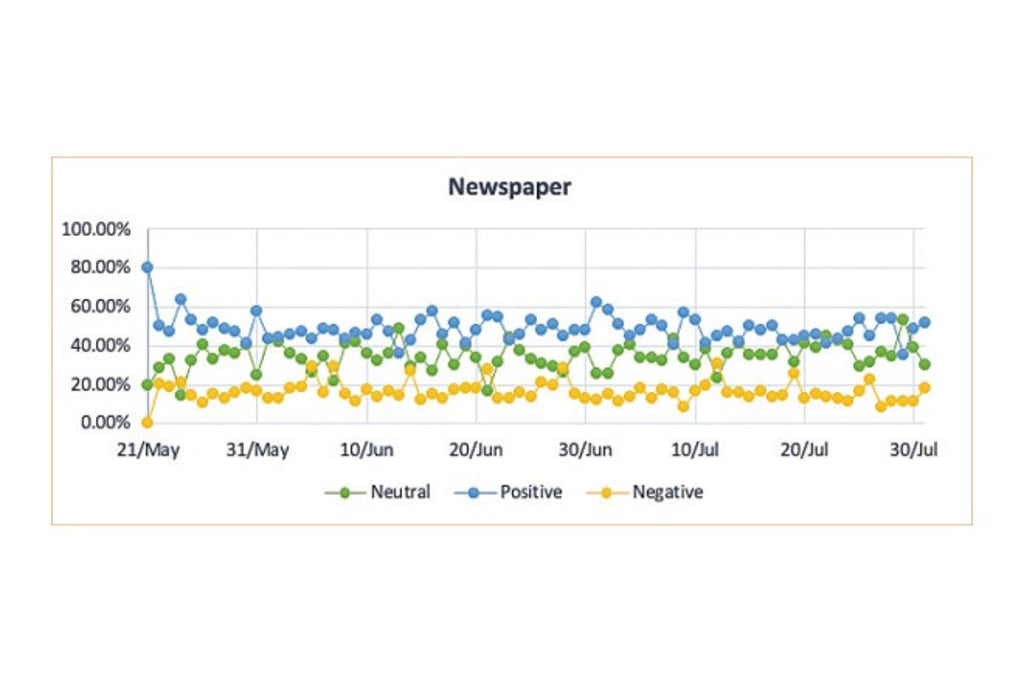
This pattern is clearer for BBS sentiments. On the other hand, we see that the pattern is different for sentiments on newspapers.
In sum, we find strong evidence of different impacts on the sentiments across various types of media and significant impacts of different authorities on the sentiments. Our sample comprises around 0.4 million posts and comments.
About the Center for Business and Social Analytics (CBSA)
The Center is committed to studying timely business and social problems by utilizing the big data available on the Internet. The data used in our research has a wide span, including social media posts, publicity, user-generated content, user likes and follows, and other social, business, and interpersonal exchanges. We draw on the strengths of faculty and researchers from diverse disciplines, such as business accounting and economics, information systems, decision analytics, finance, computer science, and humanities and social sciences, to produce evidence-based research with the aim of informing business practices and public policies.
The Center actively collaborates with other academic, public, and private organizations who share the same vision of cultivating and analyzing social big data to uncover novel insights and knowledge. We welcome academic scholars and industry practitioners to work with us on addressing emerging business and social problems for the long-term betterment of Hong Kong and beyond.